Quantum Reinforcement Learning
|
The Projective Simulation (PS) model, introduced in [Briegel, De las Cuevas, Sci. Rep. 2, 400 (2012)], is a framework for the description of autonomous embodied learning agents in artificial intelligence (whose main components are illustrated in the figure on the right-hand side). Recently, the PS model has been shown to perform well in standard RL problems [see, e.g., Mauter, Makmal, Manzano, Tiersch, Briegel, New Gener. Comput. 33, 69-114 (2015), arXiv:1305.1578; Melnikov, Makmal, Briegel, IEEE Access 6, 64639-64648 (2018), arXiv:1804.08607] and in advanced robotics applications [Hangl, Ugur, Szedmak, Piater, in 2016 IEEE/RSJ International Conference
on Intelligent Robots and Systems (IROS) (2016) pp. 2799-2804, arXiv:1603.00794]. Moreover, its memory structure provides a dynamic framework for generalization [Melnikov, Makmal, Dunjko, Briegel, Sci. Rep. 7, 14430 (2017), arXiv:1504.02247]. The central element of the PS agent is an episodic and compositional memory, storing a representation of its past experience, and allowing the agent to simulate future action. The memory can be described as a stochastic network of so-called clips (blue and green dots in the figure), some of which may represent percepts (blue), some of them represent actions (green). The decision-making process of the agent is then realized by a stochastic random walk in the clip network. In a Reflecting Projective Simulation (RPS) variant of the PS model [Paparo, Dunjko, Makmal, Martín-Delgado, Briegel, Phys. Rev.X 4 031002 (2014)], the goal is to output actions according to a particular distribution which can be updated and hence changes throughout the learning process. The RPS framework is amenable to quantization, and provides a quadratic speed-up in the decision-making with respect to its classical counterpart, which has been implemented in an ion trap quantum processor [Sriarunothai, Wölk, Giri, Friis, Dunjko, Briegel, Wunderlich, Quant. Sci. Techn. 4, 015014 (2019)]. |
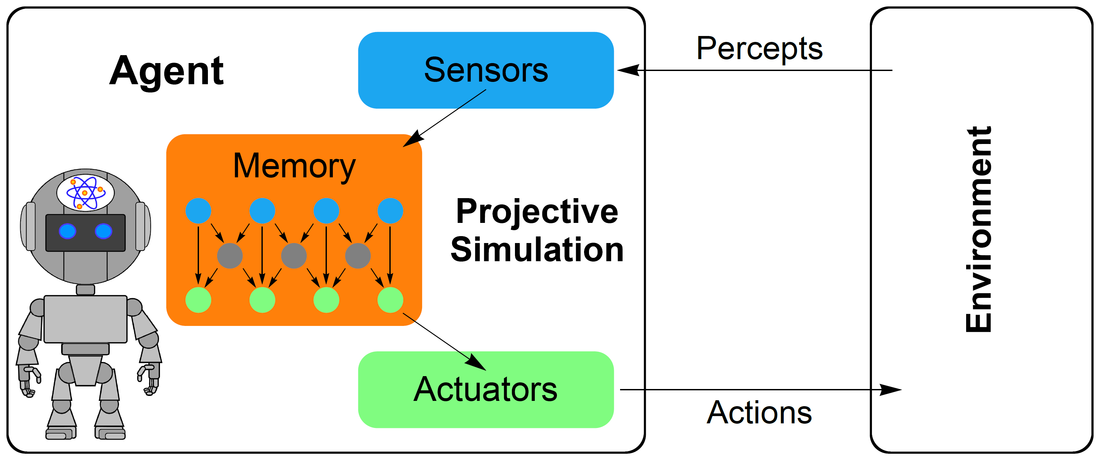
Scheme for a projective simulation agent that interacts with its environment via sensory input (percepts), and action on the environment that is conducted using a set of actuators.
The sensors and actuators are linked to the memory, which relates new perceptual input to the agent’s past experience. Figure from [Sriarunothai et al., Quant. Sci. Techn. 4, 015014 (2019)].
The quantum-mechanically sped-up decision-making process of the RPS agent depends on the ability to implement operations conditionally on the state of a control register. At the same time, the updating procedure of the memory that goes along with learning means that it is desireable for the agent to have a fixed hardware that can add control to arbitrary unitary operations. Since there is no generic way of achieving this, we have investigated the possibilities of implementing this coherent controlization procedure specifically in trapped ions [Dunjko, Friis, Briegel, New J. Phys. 17, 023006 (2015)] and superconducting qubits [Friis, Melnikov, Kirchmair, Briegel, Sci. Rep. 5, 18036 (2015)].
|
